YouTube에 올라온 Andrew Ng 교수님의 Machine Learning 영상을 보고 네 번째 Lecture를 듣고 캡쳐 및 내용을 적은 포스트이다.
4.1 Multiple Features
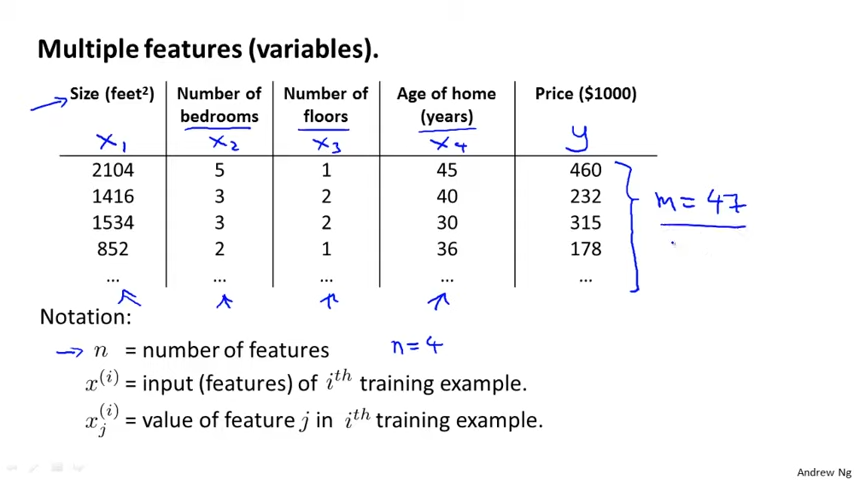
X^(1) = [ 2104
5
1
45 ] 의 feature를 갖는다. (1)은 테이블의 첫 번째 행을 의미한다.
X^(1)에서 j가 3일 경우, Age of home 값인 1을 가르킨다.
이렇게 여러 개의 feature를 갖는 경우, h(x) = theta 0 + theta 1 이 아닌 아래 hypothesis가 성립된다.
h(x) = theta 0 + theta 1 + theta 2 + theta 3 + theta 4

이것을 Mutlivariate Linear Regression 이라고도 부르다.
4.2 Gradient Descent For Multiple Variables

J(theta 0, ..., theta n)은 J(theta)로도 표현가능하다.
feature 개수가 1개로 고정되었을 때와 1개 이상일 때의 표현식은 아래와 같다.

4.3 Gradient In Practice - Feature Scaling
Gradient Descent가 더 잘 동작하게 만드는 2가지 방법이 있다.
첫 번째는 Feature Scaling 방식이다.
4.3.1 Feature Scaling

feature 범위가 너무 넓으면 또는 너무 좁으면 Global optima를 찾는데 오래 걸리기 때문에 대략 -1 이상이고 1이하인 범위(비슷한 범위)에서 J값을 찾도록 하는 방식이다.
4.3.2 Mean Normalization

x를 x - M로 바꿔서 범위 값으로 나누는 방식으로 J값을 찾는다.
4.3.3 Learning Rate

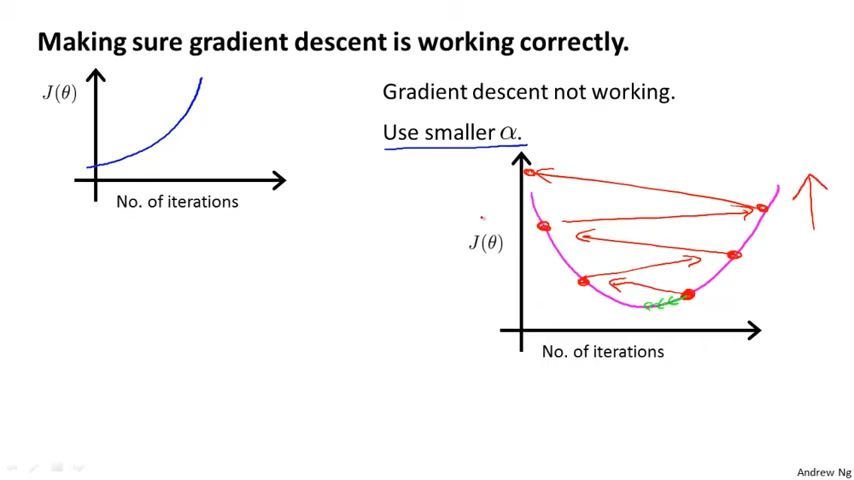
α가 충분히 작다면, J(θ)는 매 interation때마다 감소할 것이다. 그러나 α가 너무 작으면 Gradient Descent가 모이는데 느릴 것이다. 따라서 α를 선택할 때, 아래 범위의 값을 선택하는 것을 추천한다. 또한 α(Learning Rate)를 3배씩 증가 시켜라. 즉 0.001 → 0.003 → 0.009 → ... 와 같이 말이다.
..., 0.001, 0.01, 0.1, 1, ...
4.5 Features and Polynomial Regression


4.6 Normal Equation (정규방정식)

위 이미지는 테이블에 정의된 feature를 Matrix로 옮겼을 때의 예시이다. 아래는 feature를 Matrix로 옮기는 과정을 일반화한 것이다.
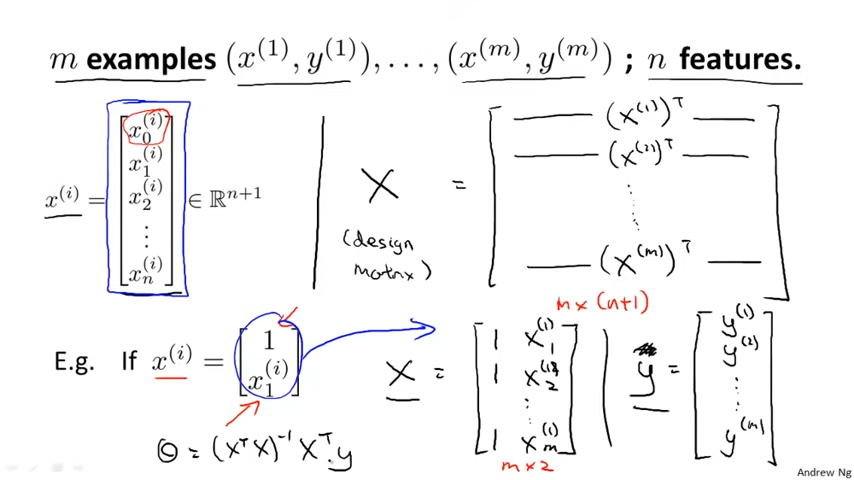
Linear Regression에서 Gradient Descent로 theta를 찾는 방법 대신 Normal Equation을 사용할 수 있다.
아래는 장단점을 적어놓은 것이다.

4.7 Normal Equation and Non Invertibility
Normal Equation을 수행하다가, Matrix X가 "Singular Matrix" 또는 "Degenerate Matrix"일 경우
X^TX가 Non-invertible한 문제가 발생하기도 한다.
2가지 주된 원인은 아래와 같다.
1. Redundant features (linearly dependeny)
e.g. x1 = size in feet^2, x2 = size in m^2
2. Too many features (e.g. m <= n)
: Delete some features, or use regularization
'Study > Machine Learning' 카테고리의 다른 글
| Lecture 7) Regularization (0) | 2022.01.23 |
|---|---|
| Lecture 6) Logistic Regression (0) | 2022.01.23 |
| Lecture 3) Linear Algebra (0) | 2022.01.23 |
| Lecture 2) Linear Regression With One Variable (0) | 2022.01.22 |
| Lecture 1) Machine Learning 이란? (0) | 2022.01.20 |




댓글